Linux C环境配置
关键词:Linux,c/c++,vim,gdb
作者:BIce 创建时间:2012-01-08 14:29:00
1. 简介
Linux是一个开源的类Unix系统,它与Unix相兼容,使用相同的Shell外壳,又因其开源性质受到大多数技术控的喜爱,其中由于其稳定完善的功能和强大社区的支持,使用Linux的方面越来越广泛。嵌入式领域中是Linux非常适合的舞台,可修改的轻量级操作系统非常适合嵌入式领域,而由于最近所兴起的开源硬件思想,Linux的重要性日益突出,而在Web开源开发中由于LAMP受到了大力推崇,Linux在服务器领域也是顺风顺水,越来越流行(Facebook都用,还有什么可怀疑的呢)。另外在Linux中,C/C++编程与在Windows编程中有了比较大的区别,具体请见《Unix环境高级编程》,不进行赘述。
而由于本人之前一段的工作和未来所要从事的方面都与上述有所交集,遂决定转入Linux阵营,由于工作需要捡起C/C++继续学习中。下面是本人关于环境搭建的一点总结,以免失忆。本人菜鸟一名,一切从简,有错误欢迎拍砖。
另外,Linux有许多的版本,个人比较喜欢Debian,自己使用Ubuntu。
2. 编辑器—Vim
在Linux C++编程环境中,也有如VS的继承开发环境,如CodeBlock,Eclipse,QTCreator等等,但最受推崇的文件编辑器要数Vi和Emacs了,Vi作为最受推崇的编辑器有非常强大的功能,而Emacs也是同样,由于本人对Vi比较熟悉,对Emacs还不很了解,目前就使用Vim(Vi的增强)作为编辑器进行配置介绍。
2.1安装
在Ubuntu中安装一个Vim和其他任何软件一样都有两种方法,编译安装和apt-get安装,这两种安装方式一般都可,如果可行的话推荐apt-get,比较方便,也不用自己处理依赖,不过使用这种方式需要找好apt-get的源,进行配置后才可进行(附两个源的链接http://blog.sina.com.cn/s/blog_4b8de29f0100mkhw.html http://wiki.ubuntu.org.cn/index.php?title=Qref/Source&variant=zh-cn)。
在安装完Vim之后,就可以进行使用了,这时虽然可以使用Vim,但是此时的Vim的功能还是非常少的,而Vim的功能扩展主要是通过安装插件进行,我们所说的配置Vim其实主要就是配置Vim的插件,关于插件,推荐一篇博文,非常详细的介绍了各种插件的安装以及用法:http://blog.csdn.net/wooin/article/details/1858917 。
而插件相关的两个比较重要的文件是$Home/.vim文件夹,其中的plugins可供我们放置下载后待用插件,如果此文件夹不存在可以手动创建,而$Home/.vimrc这个文件就是我们Vim的主要配置文件,所有的插件配置都在此文件中进行。
下面主要记录下我自己的插件配置,我的配置极为简单,仅为记录
2.2我的插件配置
2.2.1使用的插件有:
1. CTags:支持对代码文件进行扫描生成tags文件的工具,是taglist等插件的基础,可以用于在源文件中进行跳转。如函数名上使用Ctrl+] 可以调整到定义处,Ctrl+T可以跳回原点。注:在每次源文件修改后原则上都要重新生成tags才可正常使用。
2. Taglist:在CTags的基础之上,可用在源文件中查看它的变量和函数名等等
3. WinManager:可用用来以列表的形式查看源文件结构,可用以Vim屏幕切分管理,源文件我一般用NERDTree来进行查看
4. NERDTree:一个很强大的文件浏览器插件,可以用树形结构给出文件的整体格式,使用起来非常方便,建议使用
5. QuickFix:标准Vim插件,在窗口下面显示结果的窗口,使用方式见:help quickfix.
6. MiniBufExplorer:在同时打开多个文件的时候,方便多个文件的切换插件
7. New-omni-completion:自动补全功能,基于Ctags,可以完成代码的提式和自动补全等
8. Vimgdb:在Vim中集成gdb的工具,可以直接在Vim中执行调试,很不错的工具。
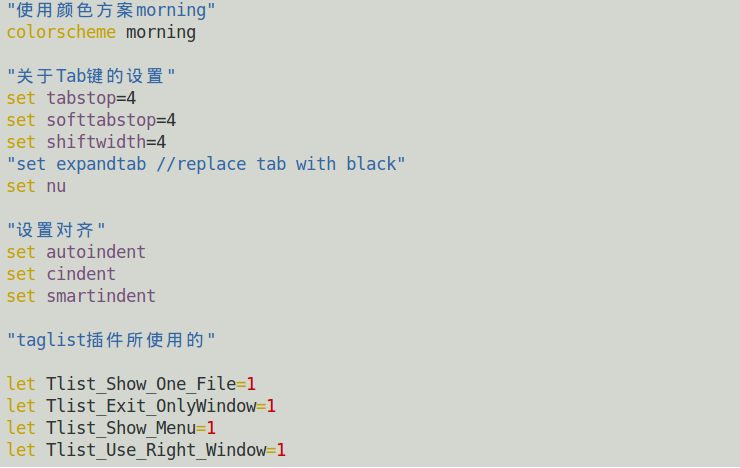
经过上述插件的配置,我的基本Vim配置就完成了,当然个别插件的安装都不是那么容易的(比如vimgdb),具体的安装方法请Google之,不赘述。现在Vi基本已经可以当作IDE进行使用了,也拥有了基本的一些功能。下面是我的.vimrc文件配置截图
2.2.2配置截图


关于Vimgdb的安装几点记录,参考教程:
http://easwy.com/blog/archives/advanced-vim-skills-vim-gdb-vimgdb/
1)打完补丁,编译完成后,记得拷贝vimgdb_runtime文件夹
2)再.vimrc里设置:run macros/gdb_mappings.vim的映射
3)然后按F7,开启gdb正式映射模式,可以正常使用gdb_mappings.vim里面定义的快捷键
4)使用先file fileName,在ctrl+B加断点,用大写R运行程序,大写C继续,ctrl+P打印变量值,可以:bel 20vsplit gdb-variables打开变量监视窗,用v命令选中变量,用ctrl+P将变量放入监视窗口,可以用createva x+2的方式将变量的计算值也放入窗口
3. 编译器—gcc
3.1简介
gcc全称是GNU C Compiler,是GNU项目中最杰出的软件之一,gcc现在已经是一个编译器软件家族,它已经不仅能支持C,现在还可以支持C++,Java,Objective C, COBOL等语言。(C++的编译器为g++,源文件默认后缀为 cxx, windows下一般为cpp)
gcc编译程序的时候整个过程分为4个阶段:
1. 预处理Pre Processing ----- 调用预处理器cpp
2. 编译 Compiling ----- gcc 自身执行
3. 汇编 Assembling ----- 调用汇编器as
4. 链接 Linking ----- 调用链接器 ld
3.2 gcc用法
gcc 的基本用法是
gcc [options] [filenames]
常用的选项有:
|
-c |
只编译,不连接成可执行文件 |
|
-o outfile |
确定输出文件的名称 |
|
-g |
产生gdb需要的符号信息,如果需要调试就必须加入此选项 |
|
-O |
对程序进行优化编译、连接。编译过程较慢,一般在发行版加入选项。 其中有O0-On,0是不优化,n越多优化越高, |
|
-O2 |
比O更好地优化编译、连接。编译过程更慢 |
|
-Os |
对目标文件大小进行优化 |
|
-I dirname |
将dirname目录加入到程序头文件目录列表中,是预编译使用的参数,就是相当include_path,(找不到再到dirname中找) |
|
-L dirname |
将dirname目录加入到程序函数库文件的目录列表中,链接过程中的参数,(链接程序ld会在系统默认路径/usr/lib中找库文件,加上此参数则首先到dirname中找再去/usr/lib找),如果用到多个目录需要依次指定,链接器ld会按顺序进行查找 |
|
-l name |
链接时装载名为libname.a的库,此库在系统默认库目录下或者由-L指定的目录下。 |
|
-MM |
编译时自动寻找源文件中包含的头文件,并生成依赖关系 |
将编译过程分单独步骤执行
|
-E |
预编译后停下来,生成后缀为.i的预编译文件 |
|
-S |
汇编后停下来,生成后缀为.s的汇编源文件 |
|
-c |
编译后停下来,生成后缀为.o的目标文件 |
警告提示功能选项
|
-pedantic |
在gcc发现不符合ANSI/ISO c标准的源代码时,产生警告信息 |
|
-Wall |
使gcc产生尽可能多的警告信息 |
|
-Werror |
使gcc将警告当作错误进行处理 |
|
-Wcast-align |
在源程序中地址不需对齐的指针指向一个地址需要对齐的变量地址时,产生一个警告,如字符指针指向int *地址则会出现此警告. |
|
-v |
输出gcc工作的详细流程 |
|
--target-help |
显示目前所用的gcc支持的CPU类型 |
|
-Q |
显示编译过程的统计数据和每一个函数名 |
除-I,-L,-l外其他的库操作选项
|
-static |
强制gcc用静态链接库.a。默认的执行方式是优先使用动态链接库.so,只有在动态连接库不存在的时候才使用静态链接库 |
|
-shared |
生成一个共享的目标文件(就是动态库),它能够与其他目标一起链接生成一个可执行文件。 如gcc –Wall –c –fpic file1.c file2.c 其中-fpic指定生成的.o文件可被重定地址,pic是位置无关代码的意思 然后gcc –share –o libName.so file1.o file2.o 编译生成动态库文件 |
调试相关选项
|
-g和-ggdb |
在gcc编译时加入调试符合,方便调试 |
|
-p和-pg |
编译时将Profiling信息加入代码中 |
|
-save-temps |
编译过程中保持生成的中间文件,如.i,.s等等 |
交叉编译选项,用于编译与开发机不同CPU的目标代码,如开发机使x86系统,而目标平台是嵌入式等系统时,就需要此选项
|
-b |
定义目标机器 |
|
-V |
定义所指向的gcc版本号 |
|
-m |
定义一个CPU家族型号 |
链接器ld参数选项,非gcc参数,是ld程序的参数
|
-Map mapfile |
指定内存分配映像文件名,通常用map作为文件的后缀 |
|
--cref |
生成交叉引用表,如生成map文件则在map文件之后,否则在标准输出中输出。 |
|
-T scriptfile |
使用链接描述文件来代替默认的链接描述,由于在进行嵌入式开发中CPU对内存映射方式不同,需要开发者给出链接描述文件对代码段、数据段地址进行描述。(内容很多,现在还不了解) |
4. Make方式
由于程序是由模块组成的,而一个比较大的项目中这种模块很多,相关的文件很多,一次编译需要考虑如模块依赖、重新编译等很多问题(重新编译时应该只编译修改过的模块,加快速度),还需要编译很多文件,为了使编译过程更加顺利,一般我们在写c/c++的时候都要有make工具来完成对项目的编译,借助的媒介是makefile文件。生成makefile文件的方法有很多,手工书写或者程序生成皆可,以下列出的工具也都是通过间接生成makefile的方式来完成对编译的管理的。
Make命令的大体执行方式如下:make会找到当前目录下名字为makefile或Makefile的文件,找到其中第一个target执行,根据定义的依赖关系,一层一层进行编译,如果出现错误编译失败,则会因为依赖找不到而失败。
4.1makefile
首先记录Makefile的基本语法。在makefile中,最重要一点需要定义的就是文件之间的依赖关系。我们所有的工作也都围绕此项进行。
Makefile文件的主要内容为:
1) 显示规则:书写者明确定义的
2) 隐晦规则:makefile自动推导的功能
3) 变量定义:指定变量
4) 文件指示:在一个makefile中引用其他makefile;指定makefile的有效部分;定义多行命令
5) 注释:用#指定
下面给出makefile的基本语法:
1. Makefile规则:
target ...:prerequisites...
command
...
...
1) 其中target是一个目标文件,可以是object file也可以是执行文件,或者标签label(类似ant的task)
2) prerequisties指定target的依赖关系(依赖关系实际上就是目标文件由哪些文件生成)
3) target的生成规则定义于command,需要有tab引导(如果prerequisites中有一个或以上的文件比target文件要新,command的命令就会执行)
2. Makefile变量(类似c,c++里面的宏)
1) 定义:object=...,如MY_VAR=A text string
2) 使用:$(object) ,或${object}
3) 变量的声明可以在使用之后
4) 用另外一种定义object:=...前面变量不能用后面变量
另外在makefile中可以使用非常多的字符串处理函数,详细可查网上
3. 定义命令包(函数)
define run-yacc
yacc $(firstword $^)
mv y.tab.c $@
endef
调用方式$(run-yacc)
4. Make的详细执行流程
1).读入所有的 Makefile。
2).读入被 include 的其它 Makefile。
3).初始化文件中的变量。
4).推导隐晦规则,并分析所有规则。
5).为所有的目标文件创建依赖关系链。
6).根据依赖关系,决定哪些目标要重新生成。
7).执行生成命令
关于Makefile的具体写法,推荐http://blog.csdn.net/haoel/article/details/2886 上的系列文章,讲的很好,看过之后我自己简单记录在:
http://blog.sina.com.cn/s/blog_3f84210f0100yva5.html。
没有讨论到的makefile方面:模式匹配(%.o:%.c)、自动依赖跟踪(利用编译器自动生成.dep依赖文件)、隐式规则(makefile内置规则)等。
4.2 autoconf& automake
由于在比较大型程序中,makefile的维护成了比较复杂的工作,为了简化makefile的维护,就出现了跨平台GNU生成工具包:包括automake,autoconf,libtool。autoconf和automake可以自动生成makefile。关于autoconf和automake的介绍详见:
https://www.ibm.com/developerworks/cn/linux/l-makefile/ ,下面仅简单记录其功能。
此工具集的大体流程如下:

在使用此工具集的时候,我们不用书写makefile,但是要写一些替代的文件方案,主要是图中的Makefile.am和configure.in这两类文件。还需要有一个完成此流程的Shell脚本,脚本大体内容如下:
#!/bin/bash
aclocal //建立automake和autoconf工具所需要的本地环境
libtoolize -- automake //运行libtoolize工具激活automake中的libtool功能
automake --a //将Makefile.am转化成Makefile.in
autoconf //读入configure.ac(in)文件将其转化为configure的文件。这个configure也就是我们编译安装时用到的./configure命令啦,它将自动生成makefile。
automake
automake工具的输入是一系列Makefile.am文件,这些文件描述将要生成的目标以及生成它们所用的依赖,automake将Makefile.am转化成Makefile.in,Makefile.in是GNU make格式的文件,在配置脚本转化为最终的Makefile文件中作为模版的工作。结合automake内建的libtool的支持,可以生成共享库(动态库)。
autoconf
autoconf工具将输入文件configure.ac转化为名为configure的纯Shell脚本。这个configure脚本复杂收集当前生成系统的信息,并使用这些信息将模板文件Makefile.in转换为GNU make使用的makefile文件。configure会确定模板文件Makefile.in中的设置变量的具体值,用具体值将其设置量替换掉,从而完成转化过程,生成makefile文件。
configure.ac中包含描述configure脚本运行应当执行的设置检查类型的宏。
例子如下:
dnl this show the comment method in configure.ac file
AC_PREREQ(2.53) 确保autoconf版本高于2.53,如果没有达到直接退出
AC_INIT(app) autoconf首先要调用的宏,使autoconf初始化自身,app是项目名。
AM_INIT_AUTOMAKE(appexp ,0.1.00) 初始化automake
AC_PROG_CC 检查C编译器并准备好需要使用的Makefile
AC_PROG_RANLIB 检查确认能够找到构建静态库的工具
AC_OUTPUT(Makefile app/Makefile) configure.ac中另一个必须给出的宏,用于指定configure应该生成的输出文件。autoconf会遍历参数并将后面加上.in,找到相应模板,并对这些模板进行替换得到输出文件。
4.3 Cmake
关于Cmake: CMake 是一个跨平台的自动化建构系统,它使用一个名为 CMakeLists.txt 的文件来描述构建过程,可以产生标准的构建文件,如 Unix 的 Makefile 或Windows Visual C++ 的 projects/workspaces 。文件 CMakeLists.txt 需要手工编写,也可以通过编写脚本进行半自动的生成。由于CMake有图形支持工具,入手简单,加之其功能十分强大,CMake现在有了越来越多的支持者,也有很多开源项目不采用autoconf&automake而直接采取了CMake的方式,如Ogre--面向对象的图像渲染引擎就使用CMake的方式进行编译。
关于CMake的教程参见以下几个网址:
http://www.ibm.com/developerworks/cn/linux/l-cn-cmake/ http://www.cmake.org/cmake/help/cmake_tutorial.html (官方教程,足见其功能强大)
http://www.ogre3d.org/tikiwiki/Getting+Started+With+CMake 。
1. Cmake一些其他的特点:
1) 可以自动发现依赖
2) 可以进行条件编译
3) 可根据用户选择给出编译选项
4) 可以直接在CMakeList.txt文件中定义变量,供程序使用(参数传递)
5) 可以进行程序的测试。
2. CMake使用过程
1) 编写CMakeList.txt文件
2) cmake PATH
3) make 进行编译
3. CMake一共使用三个目录,source dir、build dir、install dir。在编写CMakeList.txt的过程中像是用一门特殊的语言进行编程,主要需要调用其提供的一些函数库来完成编译等一些功能。
从网上找到的官方例子:程序仅编译一个tutorial.cxx文件,我们通过CMake对此程序传递参数。
tutorial.cxx如下:

注意程序使用了我们根本没有的”TutorialConfig.h”文件
接下来我们创建两个文件,一个是TutorialConfig.h.in文件

接下来创建CMakeList.txt文件,重点来了

第1行:指定出cmake需要的最小版本号
第2行:指定项目名为Tutorial
第5、6行:设置要传递给tutorial.cxx的参数值
第9到13行:configure_file为cmake提供的库函数,它可以将第一个参数中的文件模板用已有的参数值(如Tutorial_Version_Minor)进行替换,生成出第二个参数文件,放到指定目录中。还记得在tutorial.cxx中有个没有的头文件include不?这步就是产生这个头文件。
第17行:将生成的TutorialConfig.h文件的目录加入include_path中,否则编译tutorial.cxx无法找到需要的头文件。
第20行:使用tutorial.cxx编译出结果Tutorial,类似于makefile的Tutorial:tutorial.cxx规则。
现在我们可以对其进行编译了,在CMakeList.txt所在目录下执行cmake . 会产生很多文件,重要的是Tutorial这个文件,也就是目标文件,我们执行一下Tutorial,可以看到结果是

可见,我们给tutorial.cxx传递的参数其已经收到了,并且可以正常使用。CMake官方给出的例子有很多,大体上给出了使用CMake的方方面面,可以看出CMake的功能之强大,在这里不多说,大家自己研究即可
5. 调试器—gdb
调试是一个程序员最重要的看家之宝,虽然说也可以用输出变量等方式进行调试,但是对于C语言来说源码级的调试工具还是非常重要,必须使用的。GNU调试器GDB就是这样一个源码级调试工具。
要使用它我们首先需要在gcc编译的时候加上-g选项才可。另外虽然可以外部使用GDB,但是对于我们来说如果能在编辑器里使用GDB无疑是更好的选择,在vim中使用GDB的方式之前已经说过,不再赘述。另注:尽量在生成调试代码的时候不要使用-O优化选项,否则代码的可读性会很差。
下面对GDB使用介绍主要在命令行下,图形化的X-Windows Debug为xxgdb。
5.1简单使用GDB
1. 启动GDB
启动GDB进行调试程序时,首先要将应用程序的名称作为GDB的第一个参数运行。如:gdb testapp.
2. 查看代码
启动GDB后,应用程序没有运行只是加载到GDB上,使用list命令可以查看程序的源码,list可以指定行号,如list startNum, endNum.而不带参数的运行list命令只会在当前行作中心列出源码
3. 使用断点
断点设置有很多办法,常用的方法是指定函数名加入断点,如break main ;就是在main函数处加入断点。另外可以使用info命令查看可以用的断点。还可以使用clear命令对断点进行清除。
加入断点的方式:
|
break function |
在函数上设置一个断点 |
|
break file:function |
在指定文件函数上设置一个断点 |
|
break line |
在指定行上设置断点 |
|
break file:line |
在指定文件行上设置断点 |
|
break address |
在一个物理地址设置断点 |
另外还可以使用条件设置断点,如break operator if op=2,如果op==2在函数operator处设置断点
4. 单步运行
在进入断点之后的程序运行有三种控制方法:
1) next ,n :表明单步运行,不进入函数 ,可接数字表明运行几步
2) step ,s :表明单步运行,进入函数体
3) cont ,c :表明继续执行,可接数字表明运行几步
5. 查看数据
使用GDB查看正在执行的程序的内部变量var可用display var的方法进行查看,如果结构为复杂结构,则可以用C风格的方式来访问变量。注:关于静态数据的访问,可以用文件+变量的方式进行指定,如display ‘file.c’::variable.
查看数据另外的命令是print 和printf,区别是display会让程序每次运行到断点处就显示指定的表达式值,print/printf显示一次
6. 改变数据
在调试过程中改变程序的数据,用set命令来进行,像set stack->data[9]=999 ,来修改栈中数组第10位的数据为999.
7. 检查堆栈
可以用backtrace 命令查看堆栈,来查看当前活动函数回溯以及传递的变量
5.2其他GDB相关
5.2.1多进程应用程序调试
在创建进程(fork)的时候,GDB需要跟踪一个进程,而另外一个进程则无阻碍运行,我们需要指定GDB跟踪哪一个进程,可以使用set follow-for-mode child 或者follow-for-mode parent(默认)来指定GDB跟随哪一个进程,还可以使用set follow-fork-mode ask让每次创建进程的时候GDB都询问进入哪个进程。
5.2.2多线程应用程序调试
调试多线程程序难度很大,GDB提供了一些辅助多线程调试的功能,详细Google.
多线程调试的主要问题:
1) 关于断点,一处断点可能多个线程同时可能执行到,这样这些线程可能都会被影响,可以通过break source.c :17 thread 100的方式,只对一个线程加上断点。可以用info threads确定多线程环境中当前活动的线程。
2) 切换线程,GDB只能关注一个线程:当前线程,我们可以通过thread 100的方式来切换关注的线程。
3) GDB可能会根据线程的优先权修改当前线程,可以通过set scheduler-locking on来禁止GDB自行根据优先权改变当前线程,也可以用off关闭
4) 对所有线程发送统一的GDB命令:thread apply all backtrace(也可指定某些线程)
5) 总的来说,调试这个非常麻烦,目前自己不了解。
5.2.3调试已有的进程
对一个正在运行的应用程序,GDB也可挂接到它的进程进行调试,使用attach 进程识别符 即可将进程挂起进行控制,调试完成后还可以使用detach与进程脱离,进程继续执行。
5.2.4事后分析调试
当程序运行异常出Core的时候(Core dump需要用ulimit –c unlimited来开启权限才会出现),我们可以通过GDB来查看到底出现了什么问题。使用gdb testapp core.xxx加载Core和程序,使用where来查看是具体哪个函数出问题,然后可以用bt来输出栈观察具体的情况。
6.其他
这个部分主要描述一些测试周边的部分,由于C/C++测试我也不大了解,仅仅是能简单从书上进行记录了。以后实践中补全。
6.1单元测试
在进行单元测试的时候,我们有两种方案,一种是自行编写脚手架对程序进行测试,另外一种是利用已有的单元测试系统对程序进行测试,下面主要记录现有的工具,C单元测试系统。
6.1.1 C单元测试系统
简称cut,是一种用于生成单元测试应用程序的简单架构。Cut提供了一个集成单元测试的简单环境,包括把测试整合都一起,然后生成调用和报告他们的框架用到的工具集,cut解析单元测试文件,然后把它们生成为目标代码,依次执行测试文件提供所有单元测试。
需要编写的测试用例文件需要提供的函数有三类:
1) __CUT_BRINGUP__Explode:bringup函数,类似xunit的setup函数
2) __CUT_TAKEDOWN__Explode:takedown函数,类似xunit的teardown函数
3) __CUT__xxxTest:实际的执行测试的函数
在进行测试的时候需要使用ASSERT函数来对需要判断的数据进行判断。
书写完这个单元测试文件之后,需要做的还有:
1) 使用cutgen.py工具,此工具会将单元测试文件转换为一个输出文件,此文件则为需要执行的测试文件,包含main函数。使用方法为cutgen.py test_1.c >cutcheck.c
2) 将单元测试文件,源代码文件,生成的测试文件三个进行编译,连接出可执行测试文件,如gcc –o cutcheck testapp.c test_1.c cutcheck.c
3) 执行测试文件,如./cutcheck ,测试执行并用数字和符号显示单元测试进度
另外关于C/C++的测试框架,Google有一款开源的框架gtest ,也应该很好用
6.1.2嵌入式单元测试
简称Embunit,是为嵌入式系统设计的一个单元测试框架。书写测试用例文件的形式需要给出一个.c文件,内容要求:
1) 包含embunit头文件,#include
2) 给出setup函数 static void setUp(void )
3) 给出tearDown函数 static void tearDown(void);
4) 给出测试函数 static void testXxx(void);
其中的验证和比较要使用Embunit提供的Api进行检验
使用Embunit的步骤为:
1) 给出单元测试文件(上述)
2) 给出测试的主文件,包括main函数,完成初始化测试环境并调用单元测试的文件。
3) 将测试文件,测试主文件,源文件进行编译成目标测试文件
4) 执行目标测试文件
5) 检验结果
6.2覆盖测试
GNU gcov是一个覆盖测试工具,它可以监视应用程序的执行,分析那些源码被执行,哪些源码没有被执行,以及代码被执行的次数等等。使用Gcov可以判定测试是否有效的覆盖了源码。另注:在使用gcov时尽量不要加上gcc 的-O优化选项,防止出现不一致情况。
要使用gcov,需要在gcc编译的时候给出-ftest-coverage –fprofile-arcs 选项,这样在程序运行时将生产一些包含统计信息的文件:
1) -ftest-coverage 将为源文件产生一个.bb(基本块),.bbg(基本块图),用于再现执行的应用程序的程序流程图。
2) -fprofile-arcs 将为源文件产生一个.da的文件,内容是对各个分支执行次数的统计
3) 再次运行程序时,需清除这些临时文件,否则统计会在此上进行计数。
使用gcov的方法:一般方法 gcov [options] sourcefile ,例
1. gcov source.c 指定需要查看的源文件,将返回关于程序中代码执行覆盖大体情况,还会生成source.c.gcov清单数据文件,会给出每一行代码具体被执行了多少次。
2. 执行gcov时,加入-b选项,可以查看源程序中的分支统计信息,如gcov –b source.c
3. gcov加入-f选项还可以查看函数的覆盖情况 gcov –f source.c
gcov的所有选项表
|
-v,-version |
发送版本信息,没有进一步处理 |
|
-h,-help |
发送帮助信息,没有进一步处理 |
|
-b,-branch-probabilities |
向输出文件发送分支概率(与统计) |
|
-c,-branch-counts |
发送分支计数而不是概率 |
|
-n,-no-output |
不创建gcov输出文件 |
|
-l,-long-file-name |
创建长文件名,防止出现混淆文件名的情况,每个源文件会得到独立的gcov注释头文件 |
|
-f,-function-summaries |
发送各个函数的统计情况 |
|
-o,-object-directory |
指出保存.bb,.bbg,.da文件的目录 |
6.3性能分析
GNU prof工具是一款性能分析器,用于确定程序在运行时在各个函数上耗费了多少时间,GNU prof还能识别指定函数调用了哪些函数。也需要在gcc编译时加入特殊选项,在执行时产生统计文件
使用方法:
1) gcc –pg –o testapp 加入-pg选项
2) 执行目标程序,./testapp时,会自动生成gmon.out的文件。
3) 使用gprof统计信息,gprof testapp gmon.out > test.gprof,此test.gprof文件中就保存了性能分析信息,其中的数据有:基本的程序运行时间信息、每个函数的运行时间信息、调用关系图等等。
gporf 提供了很多选项来实现其他的一些功能,在这里不叙述,详见手册。
通过对gprof的输出文件进行分析,我们就可以找到源代码的瓶颈,加以优化。但记得一定要通过数据确认瓶颈后再优化.
7.参考文献
《GNU/LINUX环境编程》清华大学出版社
《Linux环境下 C编程指南》清华大学出版社
《GNU gcc 嵌入式系统开发》 董文军,北京航空航天大学出版社
谷歌、百度、以及上述引用链接的文章